betway中国西汉姆联师生论文被软件测试与分析领域CCF A类国际会议 ISSTA 2026录用
近日,betway中国西汉姆联智能运维实验室的论文《EvidenT: An Evidence-Preserving Framework for Iterative System-Level Package Repair》被软件测试与分析领域 CCF A 类国际会议——ACM SIGSOFT International Symposium on Software Testing and Analysis(ISSTA)2026录用。
以下是论文简介:
论文标题:EvidenT: An Evidence-Preserving Framework for Iterative System-Level Package Repair
作者:赵晨宇,马明华*,张圣林,黄泽舜,孙永谦,Chetan Bansal,Saravan Rajmohan,裴丹
作者单位:必威西汉姆官网平台、微软、清华大学
1.摘要
在前一篇工作Build-bench中,研究团队从评测角度系统考察了大语言模型在真实世界软件系统构建任务中的能力,揭示了跨架构迁移与系统级构建修复远比传统代码生成任务更加复杂。进一步来看,真实软件包修复不仅要求模型能够分析故障并生成修改,还要求其在多轮构建反馈中持续保留和利用失败证据,逐步修正修复策略。
随着工具链持续演进以及指令集架构不断多样化,大规模系统级软件包构建已成为现代软件生态中的常见任务。然而,软件包在构建过程中常常会因依赖关系复杂、构建环境差异、架构约束以及多阶段验证等因素出现失败。与传统项目级程序修复不同,系统级软件包修复往往涉及spec 文件、构建脚本、源码压缩包和辅助配置文件等多种异构制品,且需要依赖外部构建服务进行多轮验证,因此修复过程更复杂、证据更分散。
为此,研究团队提出了EvidenT,一种面向系统级软件包迭代修复的证据保留框架。该方法围绕“如何在多轮修复中持续保留、组织并利用失败证据”这一核心问题,将构建反馈、历史修改、工具分析结果和领域知识统一纳入迭代感知的证据上下文中,并通过自动化工具编排完成故障定位、制品级修改和外部构建验证。
研究团队首先对真实软件系统级构建失败开展了系统实证分析,发现72% 的成功修复主要依赖依赖项、构建配置或环境设置的调整,而非单纯修改源代码。在此基础上,EvidenT 在219 个真实 RISC-V 构建失败软件包上成功修复118 个,修复成功率达到53.88%,显著优于现有智能体方法和直接使用大语言模型的修复方式;在 aarch64 与 x86_64 架构上的初步实验中,EvidenT 也分别取得41.77%和46.99%的成功率,展现出良好的跨架构泛化能力。
2.背景与挑战
在现代软件生态中,系统级软件包构建往往受到工具链升级、系统组件演进和硬件架构变化的共同影响。一次构建失败可能并不只是代码错误,还可能涉及依赖缺失、版本冲突、构建脚本不兼容、打包规则错误,甚至测试阶段行为异常。尤其在 Linux 软件包生态中,修复对象不仅包括源码,还包括用于描述依赖、宏定义和构建阶段的spec 文件,以及源码归档、服务文件和辅助元数据等多种制品。
现有方法在这一场景下面临明显局限。传统方法大多依赖人工规则、历史修复模式或针对单类故障的启发式策略,难以适应真实软件包中多语言、多制品和多阶段验证并存的复杂环境。近年来,基于大语言模型的程序修复方法虽在项目级代码修复中表现出潜力,但如果仅让模型直接读取日志并生成修复,其效果仍然有限。论文实验显示,直接使用大语言模型处理 219 个失败软件包时,最多仅能成功修复4 个。这说明,系统级修复不能依赖一次性“读日志—写补丁”,而需要更系统的证据管理与迭代机制。
研究团队进一步通过实证分析总结出三项关键挑战:
如何获取可操作的失败证据。真实构建日志通常冗长且噪声较多,关键错误信号往往散落在不同阶段和不同工具输出中,模型难以直接提炼出真正可用于修复的线索。
如何组织并融合异构证据。系统级修复所需的信息既包括文本日志,也包括依赖约束、目录结构、历史修改和领域知识等多类信息,若缺乏统一组织,模型容易陷入局部判断。
如何在多轮修复中保留并复用证据。软件包修复本质上是一个“分析—修改—验证”的迭代过程。若每一轮都孤立处理,模型便容易重复之前无效的操作,导致修复路径冗余甚至无法收敛。
3.核心方法与系统架构
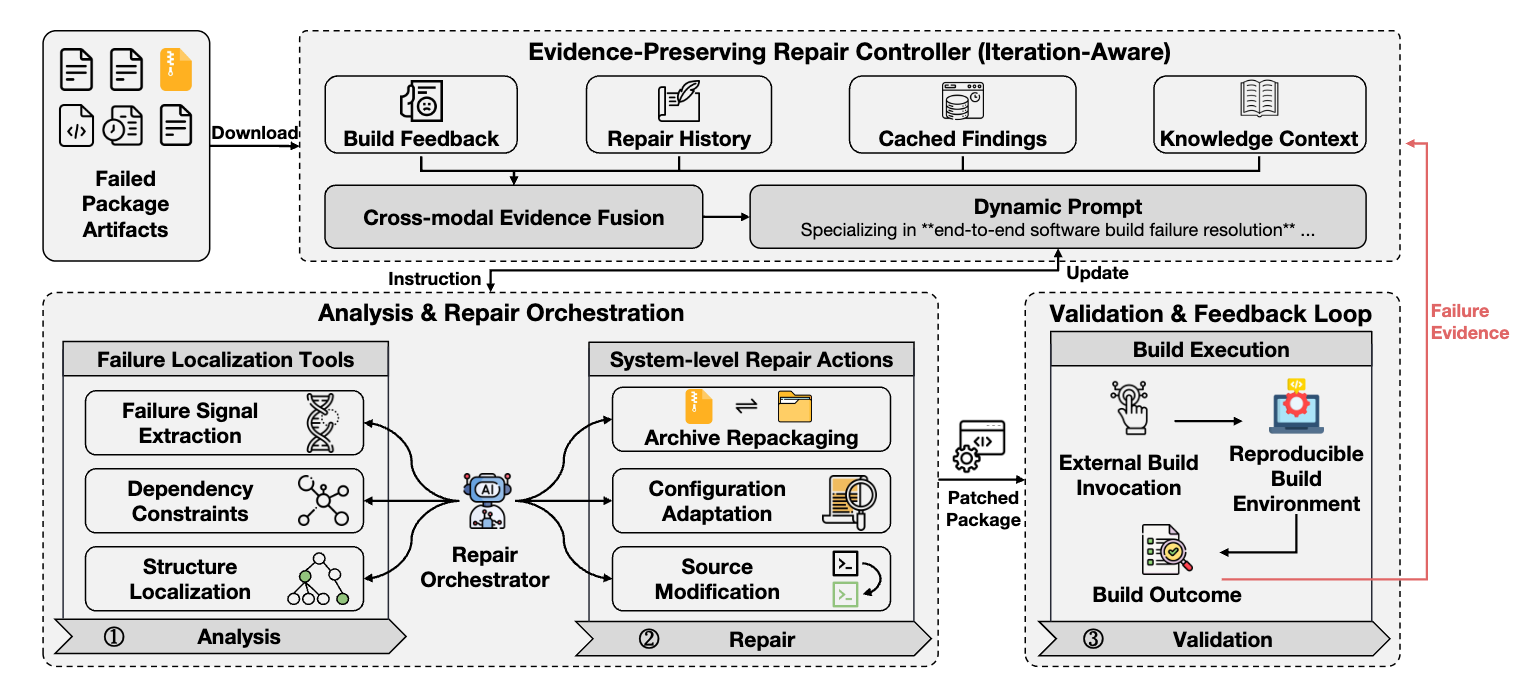
图 1:EvidenT 框架图
EvidenT 采用“证据保留控制器 + 自动化修复编排 + 外部构建验证”的整体架构,主要包括以下三个核心部分:
1)外部构建服务
EvidenT 通过外部构建环境执行真实构建,并返回最新构建结果与失败日志。这样,每一次修复都能在可复现环境中接受验证,避免仅停留在文本级或静态分析层面。
2)证据保留修复控制器
这是 EvidenT 的核心。控制器会在每一轮迭代中维护四类关键证据:
Build Feedback:当前轮次最新的构建结果与失败日志;
Repair History:之前已经尝试过的修改内容;
Cached Findings:工具分析得到的目录结构、配方解析等稳定信息;
Knowledge Context:与当前故障相关的架构知识和历史经验。
这些证据经过跨模态融合后,被放入固定的提示词槽位中,形成迭代感知的动态上下文。尤其是,失败过的修改会被显式记录为“不要重复”的负证据,从而减少模型在后续轮次中反复走回头路。
3)分析与修复编排模块
在证据控制器的指导下,EvidenT 自动调用一组模块化工具完成三阶段流程:
分析阶段:通过失败信号提取、依赖约束解析和目录结构定位等工具,从复杂构建日志与软件包制品中提炼可操作证据。其中,失败信号提取模块结合异常聚焦日志压缩、日志模板化与语义筛选,从冗长日志中识别关键错误模式,并进一步检索相关历史经验与架构知识,为后续修复提供依据。
修复阶段:根据定位结果执行配置适配、源码修改、归档重打包等系统级操作;
验证阶段:将修复后的软件包重新提交到构建服务进行验证,并将新的结果回传给控制器,进入下一轮修复。
EvidenT 的关键特点在于:它并不把修复等同于“修改源码”,而是将系统级软件包视作由配方、源码、压缩包和构建环境共同构成的整体,并在多轮证据驱动下进行协同修复。
4.实验验证与性能表现
表 1:系统级构建失败类型分布
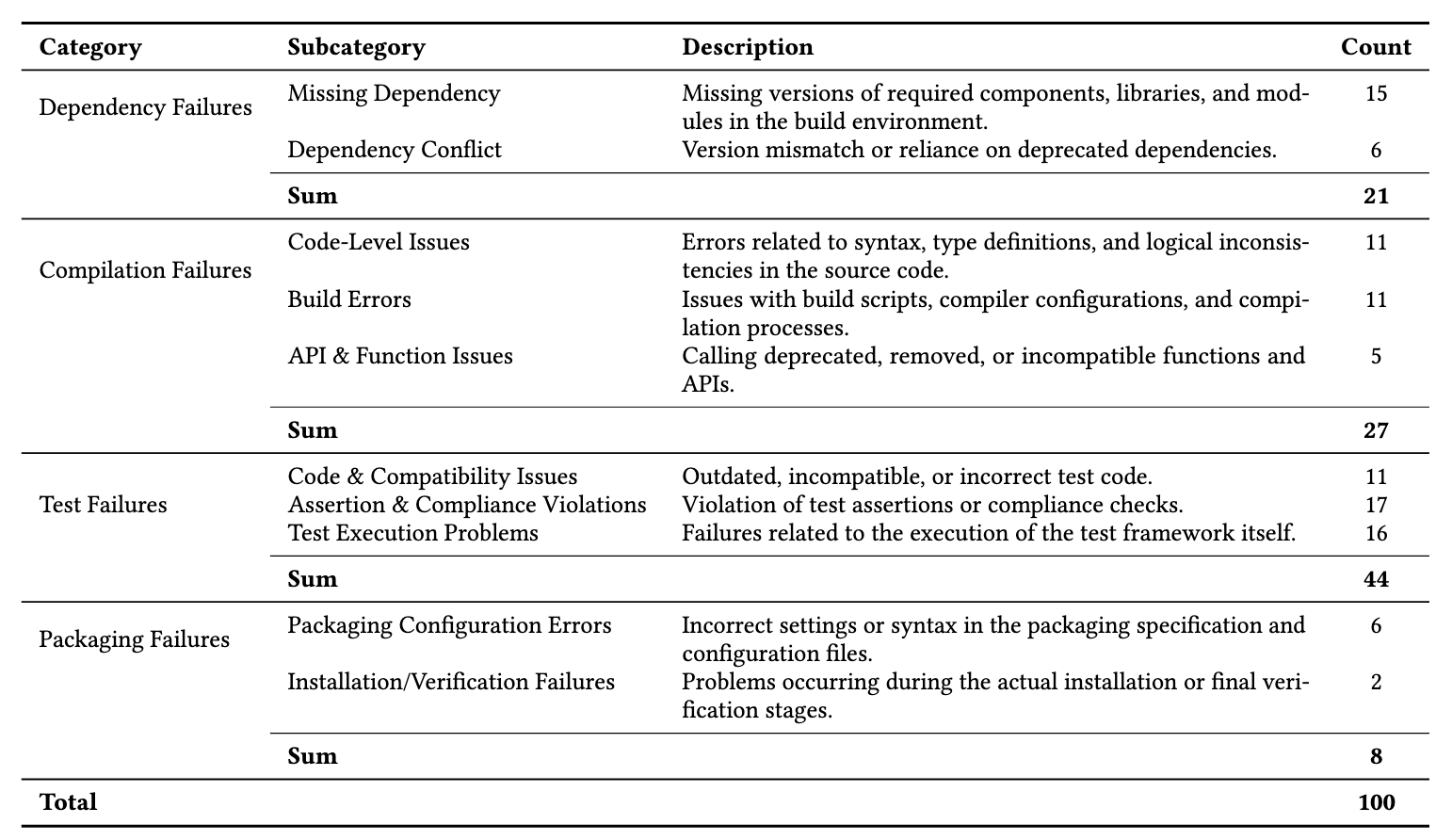
如表1所示,研究团队首先对 100 个真实失败软件包进行了人工分析。结果显示,系统级构建失败覆盖多个阶段。这说明,系统级软件包故障并不是单一类型问题,而是分布于依赖、编译、测试和打包等多个环节,需要不同类型的证据和修复动作。
表 2:真实修复中的修改类型

在对失败构建与最近一次成功构建进行对比后,研究团队发现:72%的成功修复主要涉及 spec 文件层面的修改,如依赖声明、宏定义、构建参数和环境配置调整;剩余28%的修复需要处理源码压缩包或其他辅助制品,包括新增文件、删除冲突文件或修改服务与元数据文件。
这一发现表明,系统级修复的重心往往并不在传统意义上的“代码补丁”,而在于对构建逻辑和软件包制品的整体理解。
表 3:不同方法的修复效果对比
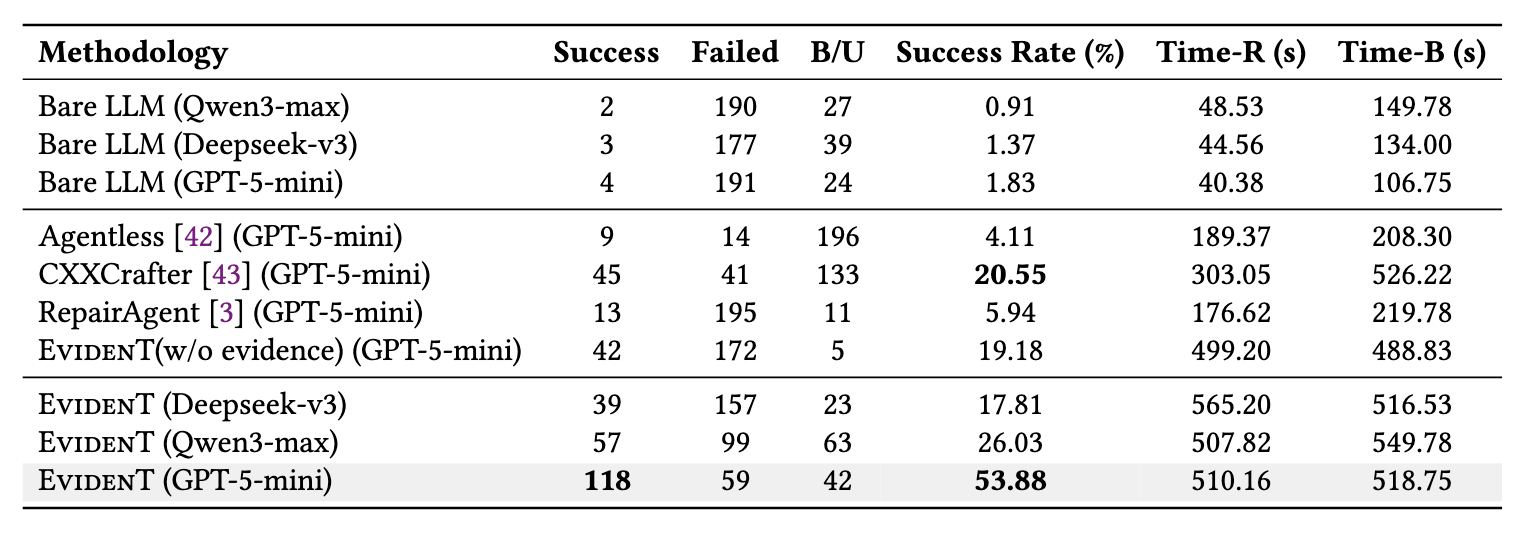
在 219 个真实 RISC-V 构建失败软件包上,EvidenT 取得了显著优势:
直接使用大语言模型修复的成功率最高仅为1.83%;
现有代表性智能体方法中,效果最好的 CXXCrafter 成功率为20.55%;
去除证据保留机制后的 EvidenT 变体成功率为19.18%;
完整版 EvidenT 成功修复118 个软件包,成功率达到53.88%。
这说明,工具访问本身并不足以带来稳定修复能力,关键在于是否能够跨轮次保留、组织和复用证据。
表4:跨架构泛化能力
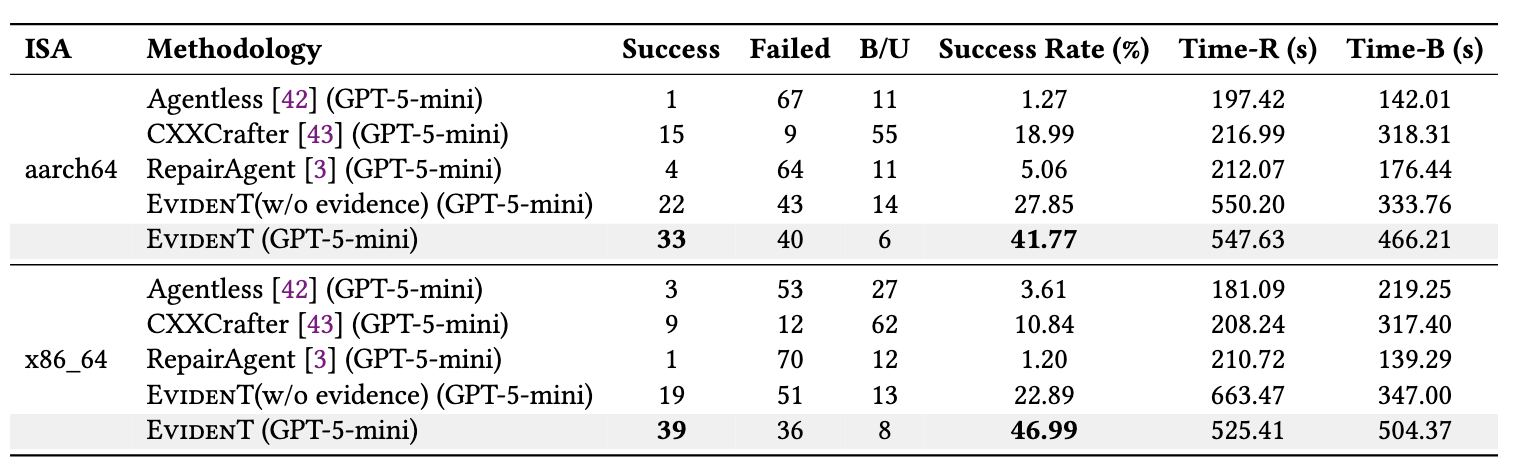
为了验证 EvidenT 是否过度依赖某一特定架构,研究团队进一步将其扩展到 aarch64 和 x86_64 场景。通过仅替换与架构相关的知识上下文,EvidenT 即可在:aarch64上达到41.77%的修复成功率;x86_64上达到46.99%的修复成功率。展示了EvidenT 的核心机制具有较好的通用性,其工作流并不依赖某一特定 ISA,而是通过“通用修复流程 + 架构特定知识”的解耦设计,实现了跨硬件生态迁移。
5.研究意义与展望
本研究首次系统揭示了真实软件系统级软件包修复的复杂性,并指出其与传统源码级程序修复存在本质差异:真正决定修复成功的,往往不是单个代码片段,而是分布在构建日志、依赖关系、配方文件、归档结构和历史修改中的多源证据。
EvidenT 的提出,为大语言模型驱动的软件维护提供了一种新的技术路径:不是让模型每次“从头猜测”,而是让其在可验证的构建环境中,基于不断累积的证据进行渐进式修复。该框架将证据保留确立为复杂系统级修复中的核心原则,为后续研究智能运维、自动化构建修复和软件工程智能体提供了重要启示。
未来,研究团队将进一步探索更加稳定和自托管的构建环境,以提升实验可重复性;同时,也将把修复目标从“构建成功”扩展到更全面的运行时正确性验证,例如回归测试、集成测试和性能评估,从而推动自动化软件维护向更高可靠性和更强实用性发展。


 津南校区地址:天津市津南区海河教育园同砚路38号
津南校区地址:天津市津南区海河教育园同砚路38号
 邮编:300350
邮编:300350