betway中国西汉姆联师生论文被软件工程领域CCF A类国际期刊 TOSEM 2026录用
近日,betway中国西汉姆联智能运维实验室的论文《Can Language Models Go Beyond Coding? Assessing the Capability of Language Models to Build Real-World Systems》被软件工程领域的CCF A类国际期刊——ACM Transactions on Software Engineering and Methodology(TOSEM)2026录用。
以下是论文简介:
论文标题:Can Language Models Go Beyond Coding? Assessing the Capability of Language Models to Build Real-World Systems
作者:赵晨宇,张圣林*,黄泽舜,金伟霖,孙永谦,裴丹,张朝运,林庆维,Chetan Bansal,Saravan Rajmohan,马明华
作者单位:必威西汉姆官网平台、北京大学、清华大学、微软
项目主页:https://aiops-lab-nku.github.io/Build-bench/
1.摘要
近年来,大语言模型在代码生成、程序修复和开发辅助中表现突出,但现有评测多聚焦于“写代码”或“修复单点缺陷”,仍难回答其能否真正参与真实软件系统构建。跨指令集架构迁移正是极具挑战性的验证场景:软件包在 x86_64 与 aarch64 间迁移时,往往同时涉及依赖、工具链、构建日志、配置脚本和多文件协同修改。
为此,我们提出 Build-bench,基于268 个真实世界构建失败的软件包,搭建“分析—修改—验证”的端到端评测流程。实验显示,当前最优模型在该任务上的最高构建成功率为 63.19%,不同模型在工具调用、反馈利用和跨架构适应性上差异显著。
2.背景与挑战
随着异构计算的发展,现代软件生态正逐步从单一硬件架构走向多架构并存。以 x86_64 与 aarch64 为代表的不同指令集架构,在寄存器组织、内存模型、编译器行为与工具链支持等方面均存在差异,这使得软件在跨架构迁移过程中极易出现构建失败、依赖冲突与运行时错误。现有软件工程基准虽然已经覆盖了代码生成、仓库级修复和真实 issue 解决等任务,但大多默认软件运行于同构环境中,并主要依赖测试用例或文本级结果进行验证。相比之下,跨架构迁移任务具有更强的系统性与工程复杂度,主要体现在三个方面:
第一,故障上下文更加复杂。跨架构构建失败通常同时涉及规范文件、依赖声明、构建脚本、编译参数与工具链配置等多层因素。
第二,代码规模和环境复杂度更高。Build-bench 中单个软件包平均包含 366 个文件、超过 5.5 万行代码,覆盖多种编程语言与配置形式。
第三,评测必须实现端到端可验证。修复是否有效,最终要以目标架构下的真实重新构建结果为准,并考察模型能否利用新日志持续迭代。
3.核心方法与系统架构
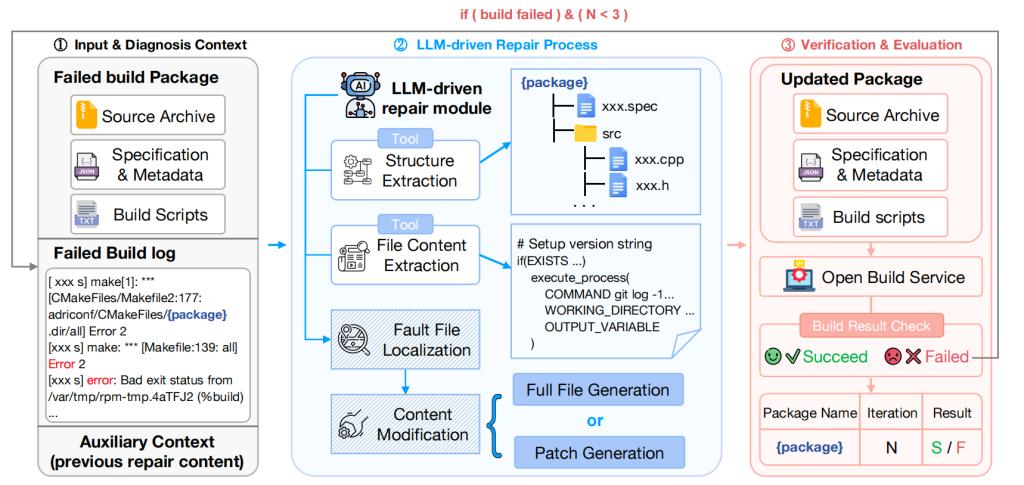
图 1:Build-bench 整体框架图
Build-bench 采用“真实失败样本 + 工具增强推理 + 迭代构建验证”的整体设计,主要包括以下三个阶段:
1)输入与诊断上下文构建
系统首先收集构建修复所需的完整上下文信息,包括:软件源代码压缩包;规范与元数据文件;构建脚本;初始失败构建日志。
这些信息共同构成模型进行故障理解和修复决策的基础。后续轮次还会补充上一轮修改、最新日志和更新后的软件包状态。
2)大语言模型驱动的修复过程
Build-bench 基于Model Context Protocol(MCP)统一暴露多种外部工具,包括:
结构提取工具:生成软件包目录结构与函数级摘要;
文件内容提取工具:读取完整目标文件内容;
内容修改工具:将模型生成的修改自动写入文件;
压缩与解压工具:支持源代码归档操作;
构建结果检查工具:获取真实构建执行结果。
模型可以根据当前故障状态动态选择工具,完成从“理解日志—定位文件—修改内容—重新构建”的完整闭环。
3)真实环境下的迭代验证
修改后的软件包会被上传至Open Build Service(OBS)进行真实构建。如果构建失败,系统将最新日志和上一轮修改反馈给模型,进入下一轮修复;若成功或达到最大迭代次数,则任务结束。
Build-bench 将最大修复轮数设置为 3 轮,兼顾成本与效率。此外,研究还设计了两类修复策略:
Full File Generation:模型重新生成完整文件;
Patch Generation:模型仅输出增量补丁。
两种策略分别对应“保持整体上下文完整性”和“提升修改精度与效率”两种典型修复范式,为分析模型在不同编辑粒度下的表现差异提供了依据。
4.实验验证与主要发现
表 1:不同模型在跨 ISA 构建修复任务中的总体表现
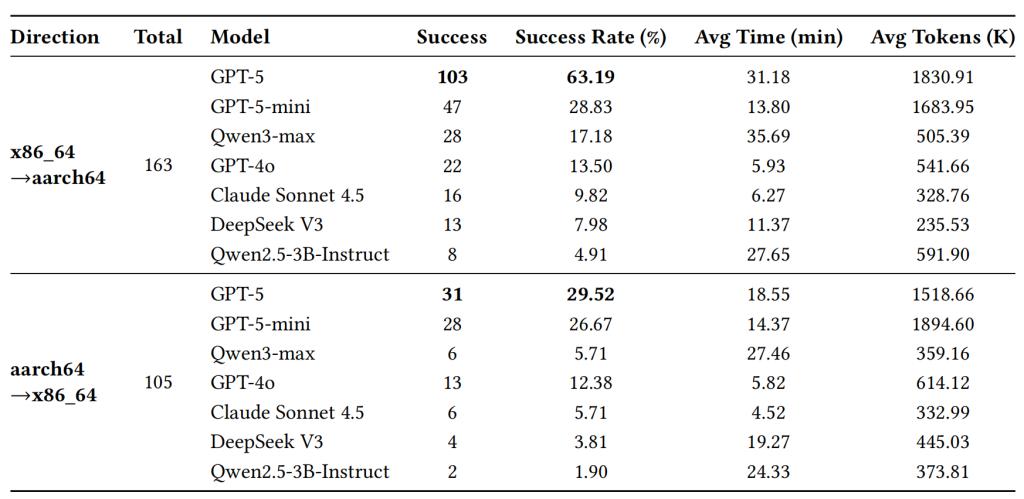
研究团队基于268 个真实世界跨架构构建失败软件包对多个代表性模型进行了评估。实验覆盖两个迁移方向:x86_64 → aarch64以及aarch64 → x86_64。
结果显示,GPT-5 在两个方向上均取得最佳表现。与此同时,不同模型之间仍存在明显差距,说明跨架构修复对模型的上下文理解、工具编排与程序性推理提出了远高于常规代码任务的要求。
表 2:迭代反馈对修复性能的提升
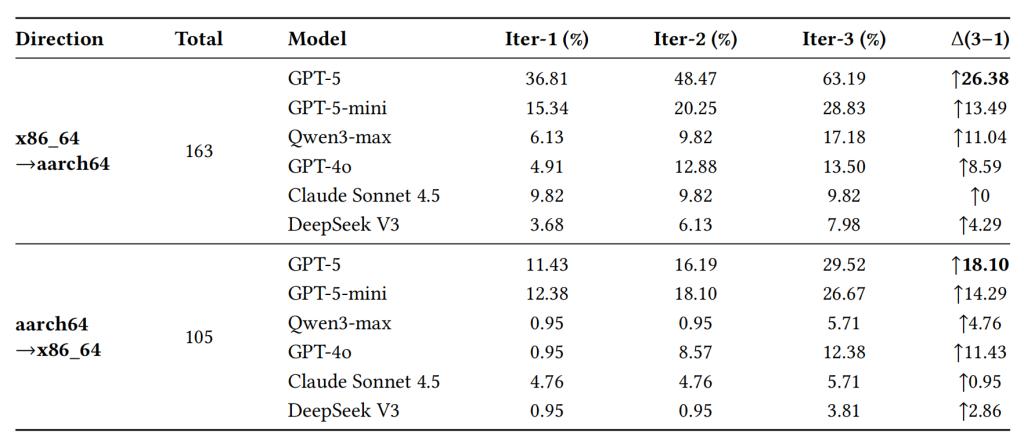
实验进一步发现,迭代反馈是提升修复能力的关键因素。与不使用工具、也不接收后续反馈的单轮 Bare-LLM 基线相比,GPT-5 在 x86_64 → aarch64 方向上的成功率由6.13%提升至63.19%,提升超过 10 倍。在三轮迭代过程中,GPT-5 的累计成功率从第一轮的36.81%增长到第三轮的63.19%;GPT-5-mini 与 Qwen3-max 也都表现出明显提升。这说明,真实构建日志中的反馈信息能够帮助模型逐步修正错误假设、补充缺失修改,并提升最终收敛能力。
研究还发现,不同模型不仅在“能否修复”上存在差异,在“如何修复”上也呈现出不同风格。
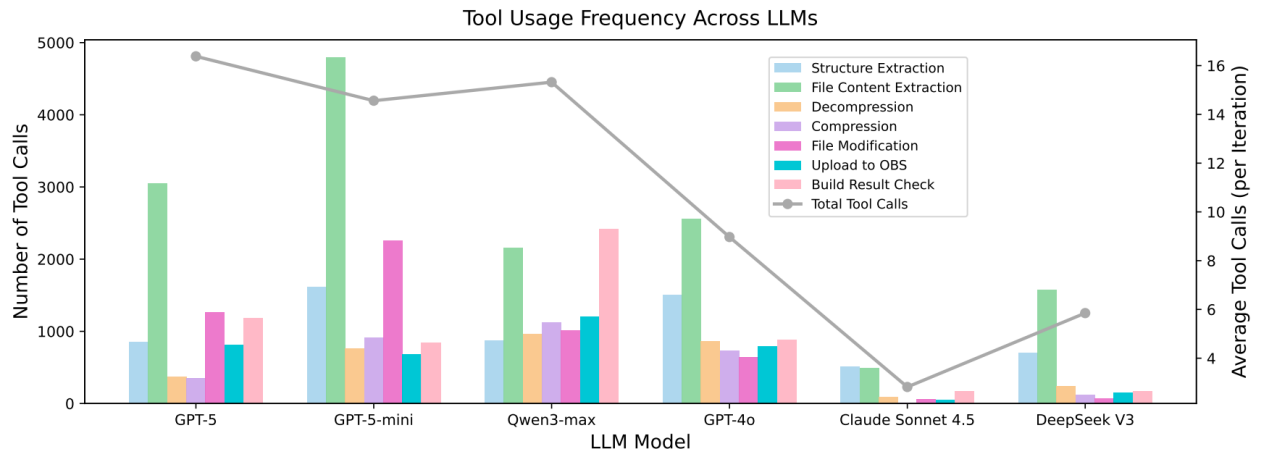
图 2:不同模型的工具调用行为
GPT-5 与 GPT-5-mini 倾向于更积极地调用结构提取、文件读取、内容修改与构建验证等工具,展现出较强的端到端任务完成能力;而部分模型则更容易陷入低效行为,例如频繁重复检查构建结果,却没有进行实质性代码修改或配置修改。该结果表明,未来评价大语言模型的软件工程能力,不能只看最终答案,还应关注其工具使用策略与过程质量。
5.研究意义与展望
本研究将大语言模型评测从“代码生成”和“单点修复”推进到更贴近真实软件工程实践的系统级构建与迁移任务。Build-bench 表明,未来模型不仅要理解代码,还要处理依赖关系、构建脚本、异构环境、外部工具和多轮反馈。
研究也揭示出当前模型仍有若干不足:对超长、交织构建日志的理解仍不充分;在多文件一致性维护方面仍有明显局限;工具调用顺序有时缺乏稳定的程序性记忆;对反向迁移场景的适应能力仍明显弱于主流迁移方向。
未来,研究团队将进一步扩展 Build-bench 至更多体系结构,并探索更可控、自托管的构建环境,以提升实验可重复性与长期稳定性。总体而言,Build-bench 为回答“大语言模型能否真正构建真实世界软件系统”提供了可量化、可复现、可扩展的研究基础,也揭示了当前模型在复杂系统级构建任务中的能力边界。
不过,评测只是第一步。面对更复杂的软件包故障,如何让智能体在多轮修复中持续保留失败证据、减少重复无效操作,并在构建反馈驱动下逐步收敛,仍是下一阶段的重要问题。围绕这一挑战,研究团队进一步提出了证据保留修复框架 EvidenT,将在本系列下一篇中介绍。


 津南校区地址:天津市津南区海河教育园同砚路38号
津南校区地址:天津市津南区海河教育园同砚路38号
 邮编:300350
邮编:300350