近日,betway中国西汉姆联智能计算实验室的论文《CKTI: A Domain-Specific Compiler for Lowering CUDA Kernels to Triton-IR》被体系结构/高性能计算领域的CCF B类国际会议——International Conference on Supercomputing (ICS 2026)录用。
作者:石昌青、陈锐*、孙羽菲、隋轶丞、张隽宇、谢宇东、王明达、明双鹏、张硕、张玉志
DOI:https://doi.org/10.1145/3797905.3800551
文章提出了名为CKTI的领域特定编译器,它通过将 CUDA 内核转换为与硬件无关的 Triton中间表示,解决了AI计算程序对特定厂商芯片的依赖问题。CKTI 利用线程模型调度算法、动态掩码映射等核心技术,成功实现了 CUDA 内核在 NVIDIA、AMD、昇腾、沐曦以及寒武纪等多种芯片上的跨平台部署。CKTI不仅实现了跨平台部署的通用性,更将性能可移植性作为其核心亮点。通过复用 Triton 和芯片自身的优化链路,CKTI能够充分挖掘不同硬件的计算潜力。实验结果表明,CKTI在多个平台上均实现了卓越的性能加速,在 NVIDIA 平台上达到 1.28 倍加速,在AMD平台上为1.17倍,在沐曦平台上为 1.14 倍,并成功解锁了在寒武纪平台上的部署,同时能够与芯片自身软件栈(如昇腾CANN)共同完成端到端模型任务,有效推动了计算生态的多样化发展。

图1 工作流
长期以来,国产 AI 芯片面临的最大瓶颈不是硬件,而是 “软件生态跟不上” 。全球 90% 以上的开发者和高性能计算程序都深度绑定在英伟达的 CUDA 平台上。CKTI这项工作使得原本只能在 NVIDIA 芯片上运行的 CUDA 内核能够被自动迁移并以可靠的性能部署到国产芯片上。这大幅降低了应用开发和迁移的成本,算法工程师可以更专注于业务逻辑,而不用担心底层硬件的差异,进而吸引更多开发者加入国产计算生态。
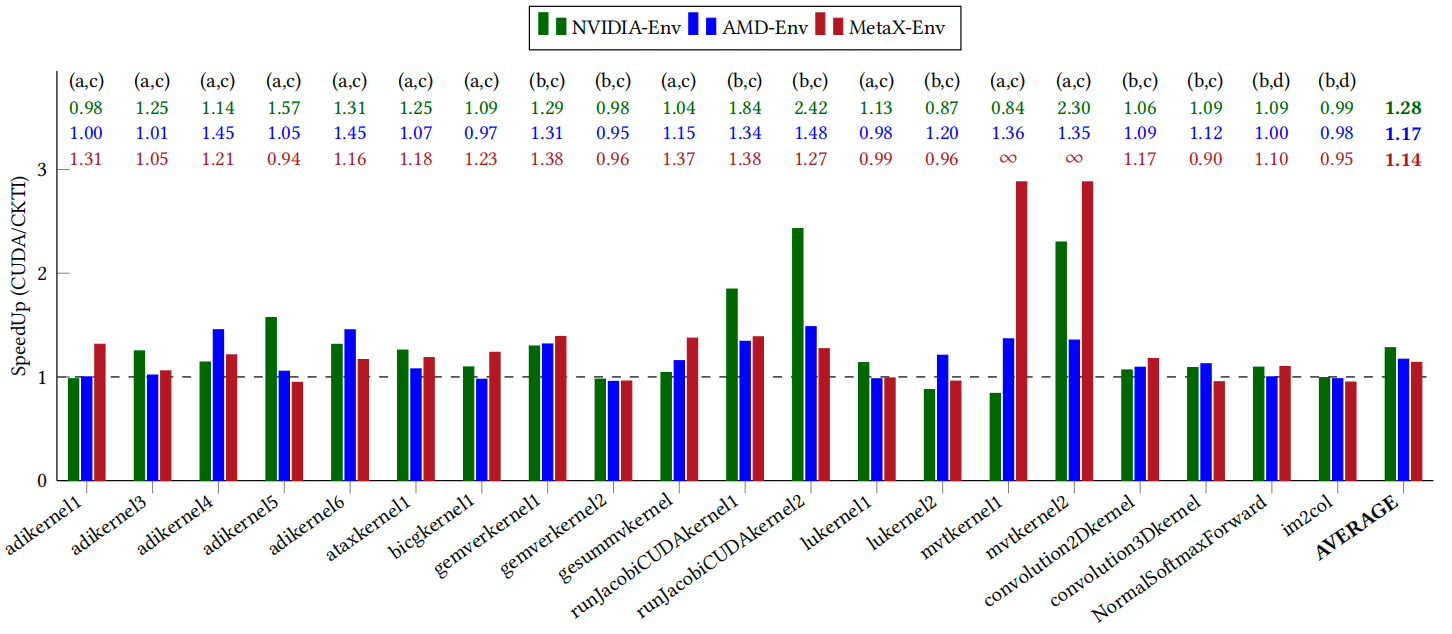
图2 GPU内核加速比
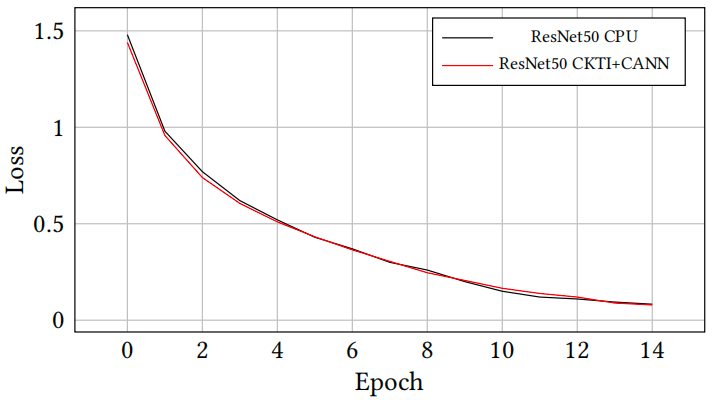
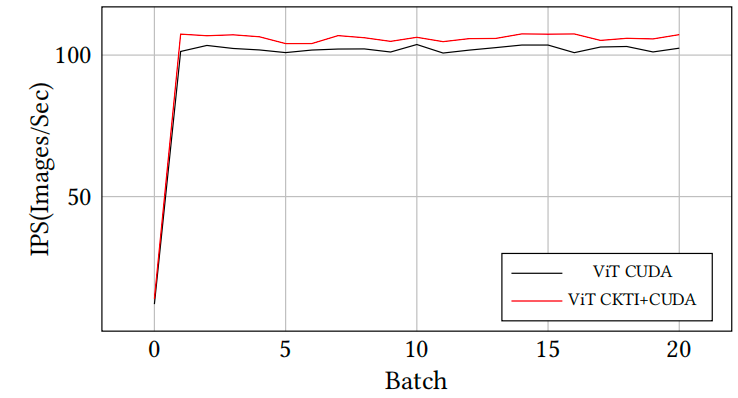
图3 端到端模型效果


 津南校区地址:天津市津南区海河教育园同砚路38号
津南校区地址:天津市津南区海河教育园同砚路38号
 邮编:300350
邮编:300350